Help and Support > Table of Contents > Value distribution analysis
Using the value distribution profiler (Pro edition only)
Often, understanding the distribution of values within a numeric field can give considerable insight into the underlying data, and possibly identify data quality issues.
To access the value distribution profiler, select the data stub with the data set you wish to profile, then select the value distribution explorer toobar button. We will look at a simple example, where we have imported some data from an SQL Server database table, and added a calculated field that determines the age of each customer based on the birth date;
TRUNC(( NOW() - [Original.BirthDate])/365)
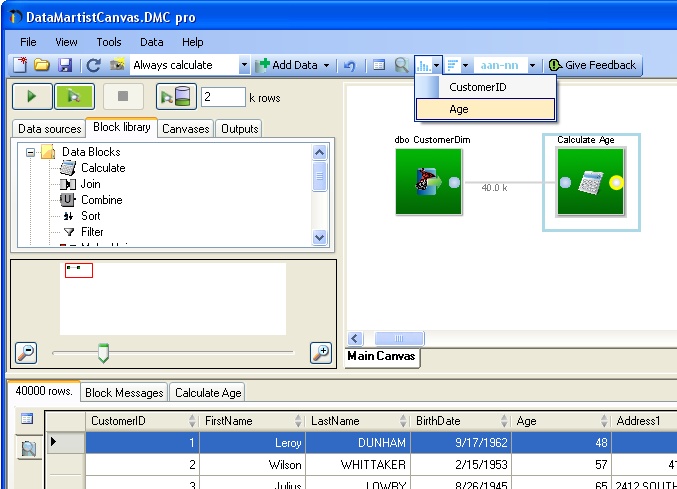
To look at the distribution of the values within this new column, select the output stub of the calculation block, then select the value distribution explorer button (
![]() ) from the tool bar and select the AGE column from the drop down:
) from the tool bar and select the AGE column from the drop down:
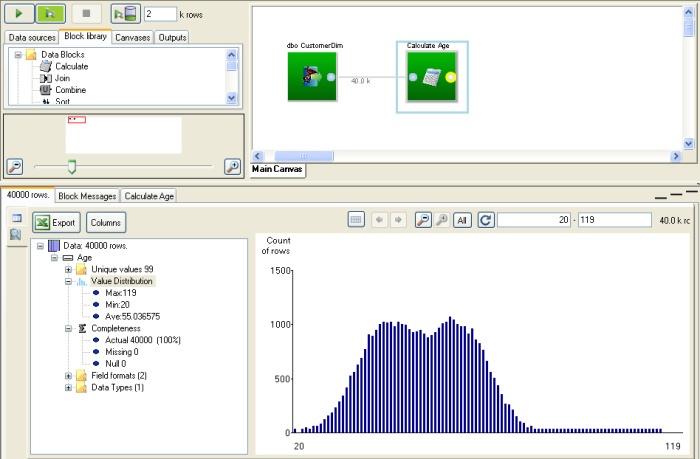
This will cause the data profiler at the bottom of the Datamartist screen to open, and the profiler will run, counting the number of values and displaying a value distribution chart. The value distriubtion counts the number of values within a series of equal size "buckets", and displays this as a vertical bar chart:
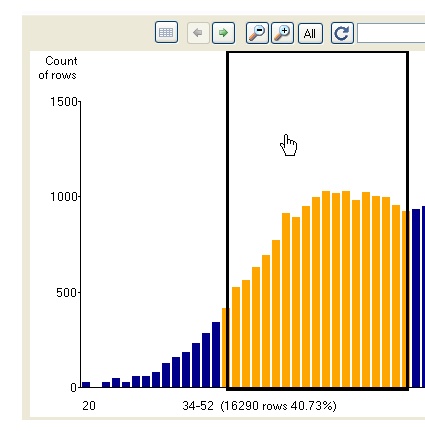
You can then use the zoom in and out, and all buttons, as well as a range selection to explore the value distribution.
By dragging accross the value distribution graph (click and then drag right or left) you can select a portion of the buckets displayed. The percentage of the overall data set (or sample if in preview mode) is displayed, and the buckets selected are highlighted.
Clicking within the selected rectangle above the bars will result in a zoom in on the selected bars.
Clicking on the bars within the selection will select a specific bar.
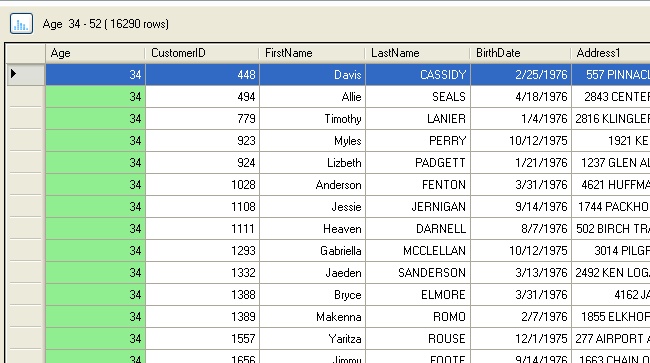
By selecting a bar or range of bars, and then clicking on the data button (![]() ), you can drill down into the rows where the value fell into the selected range:
), you can drill down into the rows where the value fell into the selected range: