
Help and Support > Table of Contents > Editing tree hierarchies
Join Part 3- Editing hierarchies using the recategorize block
Hiearchies are a very powerful way to structure and organise data- and to modify an existing set of data where parent child relationships exist. Datamartist allows the user to "override" parent child relationships, and add new structures within a data set while making the new structures flexible to many changes in the underlying data. We'll look at a simple example where we wish to create an alternate grouping of states into sales regions. First we import in the data which contains our current sales regions, define a reference, and connect that to a recategorise block;
Now if we edit the recategorise block, we can define a new hierarchy based on the data on the input. First, press the "New Tree" button to create a new hiearchy, and select he columns that you wish to include. If we select the Sales Region column then a tree view will be created, mapping the states to the various sales regions as per the input data set. If we right click on this tree view we get the following menu;
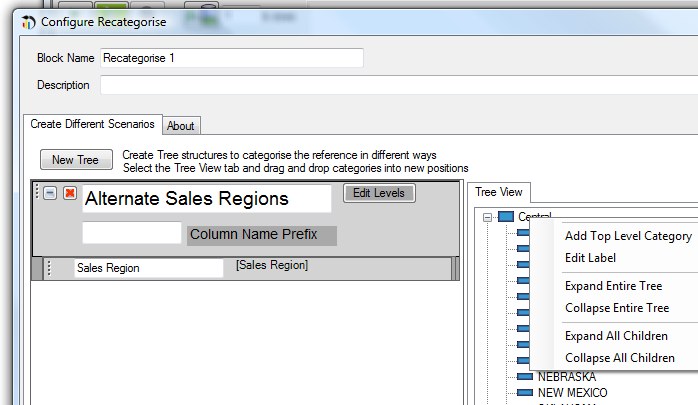
One of the things we can now do is add new members to the hierarchy- so in this case we'll add a new region called Sub Central, by selecting "Add top level category".
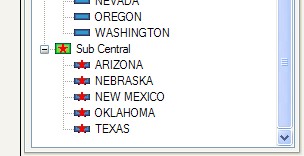
It is then possible to simply drag and drop the states we wish to be in this new sales region on the tree view. The icons on the tree view reflect which members have been moved, and which are new. This simple case only has two levels in the hierarchy, however hierarchies with many levels can be edited, and edits can span multiple levels- meaning that the user is free to edit the tree structure as desired, including adding members and modifying labels. These changes do not modify the incoming data, but are available for use in star schema blocks that are used downstream of the recategorise block. By entering a prefix for each tree the columns will be renamed, allowing both the original hierarchy and the new edited hierarchies to be part of the result set. This would let analysts compare the differences in values based on different rollup paths.