
Help and Support > Table of Contents > Preview vs Full data
Running Canvases - Preview vs Full run
 Datamartist solves the overall data canvas as a batch process. If "Always calculate" is selected, then it will run whenever a new block is added to the canvas and connected. If you wish to add
a number of blocks and connect them together before solving, you can select "Minimize calculation". Regardless of this selection, the various play buttons are used to force a run of the canvas as follows.
Datamartist solves the overall data canvas as a batch process. If "Always calculate" is selected, then it will run whenever a new block is added to the canvas and connected. If you wish to add
a number of blocks and connect them together before solving, you can select "Minimize calculation". Regardless of this selection, the various play buttons are used to force a run of the canvas as follows.
Full run (writes to outputs)
![]() The full run will refresh all data snapshots, and then solve the entire canvas using all rows, including writing to any output files and tables. It is important
to note that if parts of the canvas append data into tables, doing a number of full runs will insert rows. Often, one of the preview modes is used first to troubleshoot and design
the data transformation. Particularly in the case of transformations that append data, full run may only be used through a scheduled job, so that data is collected at
controlled intervals, and test data does not fill up the target tables.
The full run will refresh all data snapshots, and then solve the entire canvas using all rows, including writing to any output files and tables. It is important
to note that if parts of the canvas append data into tables, doing a number of full runs will insert rows. Often, one of the preview modes is used first to troubleshoot and design
the data transformation. Particularly in the case of transformations that append data, full run may only be used through a scheduled job, so that data is collected at
controlled intervals, and test data does not fill up the target tables.
Preview run (Does not write to outputs)
![]() The preview run does not refresh snapshots from data sources, but does use all the rows to solve the canvas. It does not write to outputs.
The preview run does not refresh snapshots from data sources, but does use all the rows to solve the canvas. It does not write to outputs.
Sample data run (Does not write to outputs)
![]() The sample data run does not refresh snapshots from data sources, and uses only a sample of the data. It does not write to outputs.
The sample rows used are selected from the beginning of the data set, by simply skipping rows. The number of rows to use is entered in the text box (to enter less than 1000 rows, decimals are allowed- for example 100 rows would be 0.1).
The sample data run does not refresh snapshots from data sources, and uses only a sample of the data. It does not write to outputs.
The sample rows used are selected from the beginning of the data set, by simply skipping rows. The number of rows to use is entered in the text box (to enter less than 1000 rows, decimals are allowed- for example 100 rows would be 0.1).
Stop button
![]() The stop button interupts the current run and may result in errors in the blocks that were solving at the time. Once stopped, a different run can be selected.
The stop button interupts the current run and may result in errors in the blocks that were solving at the time. Once stopped, a different run can be selected.
Sampled data on the canvas
When data is not complete (when in preview sample mode), the blocks and connectors that contain only a sample are show with dashed lines. In this example, the canvas is in preview sample mode and the number of rows has been set at 5000. As a result, the customer data, which has only 1997 rows, is not a sample- where as the larger sales data data sets are sampled, and this is shown by the dashed lines.
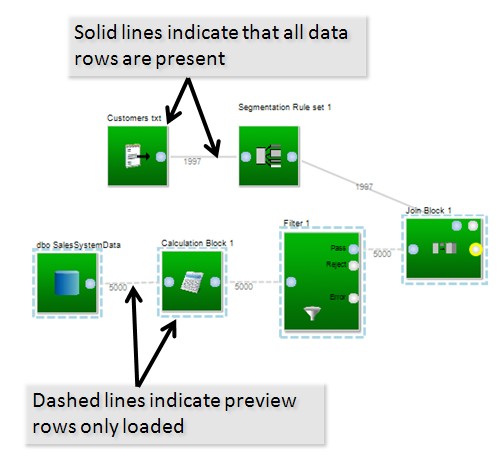
In preview sample mode, datamartist will stop loading rows from inputs after a predefined number of rows. It does not simply take the first rows, but a sample throughout the first part of the data set, skiping a certain number of rows. For very large data sets, it will not sample the entire data set, but some portion of the first rows. Datamartist does this to make it possible to build a data transformation quickly using a small subset. Then to validate the run, the user can do a "Full data run" which will force all blocks to solve with the complete data set. When working with large data sets, the user will likely want to be using preview sample mode to avoid causing delays as blocks are added and modified due to calculation time.
Remember that preview mode does not include all data
It is very important to remember that because preview mode only works with a random sample of data, it will often result in datasets and errors that do not accurately reflect the full dataset, and final result.
- Joins will often be incomplete (resulting in null values)
- In preview, duplicates might be missed, because duplicate rows are not inluded in the sample.
- For value distributions, max, min, average etc., values may be very different from the actual, depending on how representative the sample is.
While preview mode is very useful for getting a first look at what your data transforms are doing, and to test on a subset, remember to do a full preview every once in a while, and when you are chasing down issues in data, be aware that the "issue" might just be that you are not yet looking at the entire set.
Tip for using preview mode: Load reference tables
If you have reference tables that are being used to lookup information for transactions, set the preview row count so that all of the reference table rows are used. For example, if you have a product table with 1000 rows, a customer table with 6000 rows, and a transaction table with 1.5 Million rows, setting the priview row count to 6000 rows will ensure that all the products and customers are loaded in, and as a result any joins or lookups with the transactions will be successful.