
Help and Support > Table of Contents > Data Profile
Data profiler block
About:
The data profiler block profiles the data set on the input and provides a data set withthe various data profiler metrics at the output, timestamped to allow consolidation into a tracking table or file set
Block Connection Stubs |
|
|---|---|
|
Inputs
|
Outputs
|
|
|
|
Automating data profiling (Pro edition)
The data profiler block makes it possible to automate data profiling by providing data profiling data directly onto the canvas. By exporting this data into a database table it is possible to see trends in data quality, and build data quality dashboards to clearly communicate the information.
The data profiling block
By using a data profiling block, any data set at any point in your data canvas can be sampled, profiled, and the results written into a database table. The data profiling block always appends an additional column to its output containing a date time stamp of the time the data was sampled, as a result it is possible to monitor data profile trends by appending the data to a table periodicly.
The top output of the data profiling block contains the following:
- Profile Set Name - the name of the profiler block- many blocks can be used within one canvas.
- Capture Date - the date/time stamp of the profiling run.
- Column Name- the name of the column being profiled.
- Data Type - the declared data type for the column
- Null rows- the count of rows that contain the null value.
- Missing rows- for string types the count of rows containing the empty string.
- Populated rows- the count of rows that are not Null or missing.
- Completeness- the percentage of rows that are Populated (Populated/Total Rows).
- Cardinality- the number of unique values contained in the row.
- Uniqueness- the cardinality divided by the number of populated rows.
- Minimum- the minimum value within the column for numeric columns, the earliest date for date columns.
- Maximum- the maximum value within the column for numeric columns, the latest date for date columns.
- Average- the average all all values for numeric columns.
As an example, lets imagine we have a customer table that we want to monitor: We would connect a data profiling block to the output of the import block, and defined which columns we want to profile;
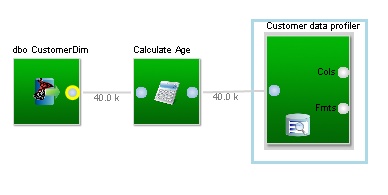
We connect the data profiler block (here we have named it "Customer data profiler") to the output of the calculation block holding the data set we want to profile.
Next, we click on the data profiler block (or right click and select "Edit") and we will be presented with the properties for the profiler in the bottom area of Datamartist;
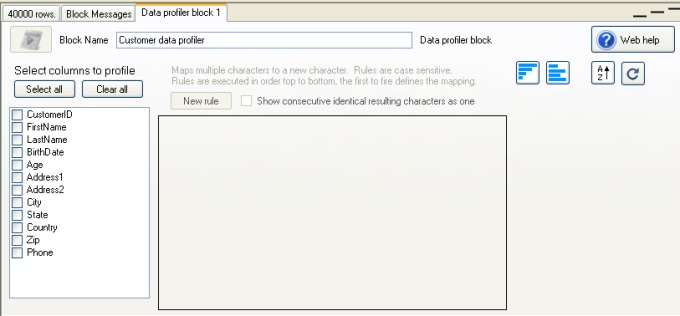
We then select all the columns that we wish to profile with this block. When we select a column in the check box list at the left, the data format rules that are in use for that column are displayed to the right;
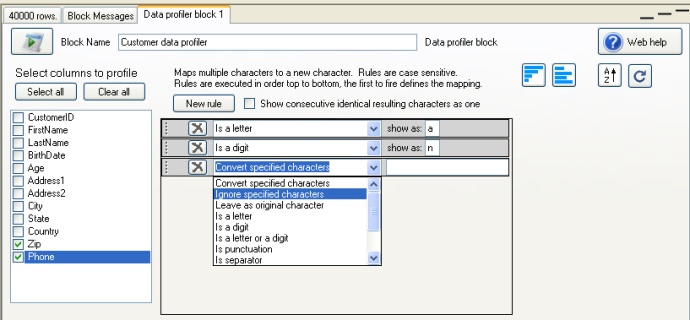
These formating rules work just as they do for the data profiler (only in the Pro version), and for each column, a custom set of data format rules can be defined.
By dragging the rules up and down, the order can be changed. This is important, as the rules are solved from top to bottom, as soon as the character being
considered satisfies a rule, it is replaced and any subsequent rules are ignored for that character. For example: a rule mapping the letters "a", "c" and "f" to the data format character
"X" must be placed before the rule "is a letter" or it will never be reached;

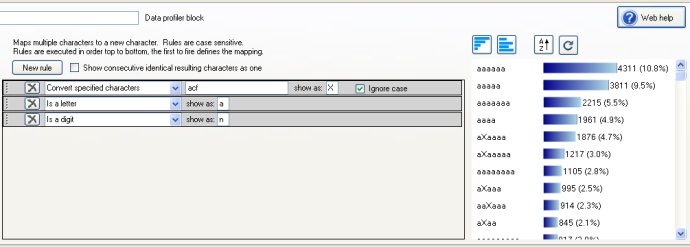
To the right of the rule editing area, is a previewer that can be used to see the result of the rule set on the data;
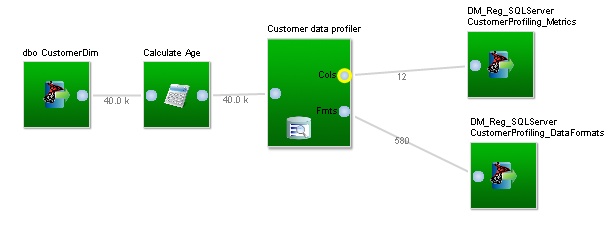
Writing results to a database table
The final step in creating an automated data profiling task is to write the results of the profiling into a database table. We can do this by connecting two database table export blocks to the outputs of the data profiler.
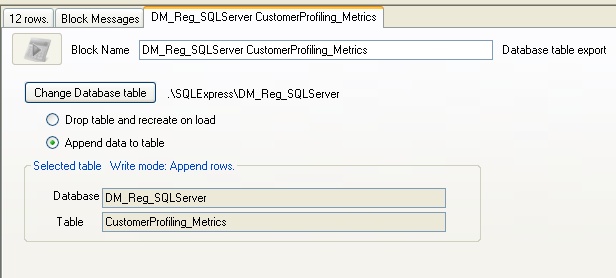
Because we want to APPEND the data to the table, (so that we can keep the historical data profiling results), we need to set the database export blocks as shown, using the radio buttons to append rather than overwrite the table.
Finally, if we want to schedule this profiling job, we can write a batch file (as described int the documentation under "Running Datamartist from the command line"). In this way, we can have a fully automated data profiling task that continues to populate the database tables, which can then be the source for data quality dashboards.