Help and Support > Table of Contents > Using references with Deduplication
Star schema part 2- Defining a reference and mapping away duplicate records
As has been seen in part one, the star schema block can be used directly with data sets to perform a simple star schema join. In this section we will show how by first preparing the reference using the Reference and the Deduplicate blocks, the star schema can be even more useful.
Duplicate records- Duplicate keys vs Duplicate reference members
When talking about duplicate data, there are two key types. They are both duplicates, but they require different approaches and are dealt with in different blocks within Datamartist.
Duplicate Keys
Duplicate keys occur when two rows in the table try to use the same unique identifier. For example, if two rows in a data set both try to use the customer_ID "564" then this is a case of a duplicate key. A field that is meant to be unique is not.
Duplicate Reference
Duplicate references occur when two rows in the table are fine in terms of the unique identifier, but refer to the same real world thing. Staying with the customer example, if both customer_ID 564 AND customer_ID 789 refer to the same customer, we have a duplicate reference. In terms of the database there is no issue, since each key has a unique value- but from an analysis point of view, clearly we don't want to see the data for a single customer split between two keys- and by having two records we can have issues such as conflicting mailing addresses, multiple credit scores etc.
Datamartist can resolve both types of duplicates, and in fact must resolve them in order- first the duplicate keys must be resolved, then it is possible to identify and map away any duplicate reference.
The reference block
The reference block is used to create a reference set of data- a reference set is a set that has a unique key defined. The reference block itself allows the user to determine which keys are unique, and to pick one or more columns that will uniquely identify the reference.
Lets look at a first example of US cities. We'll load in the US city census text file, and connect a reference block to its output.
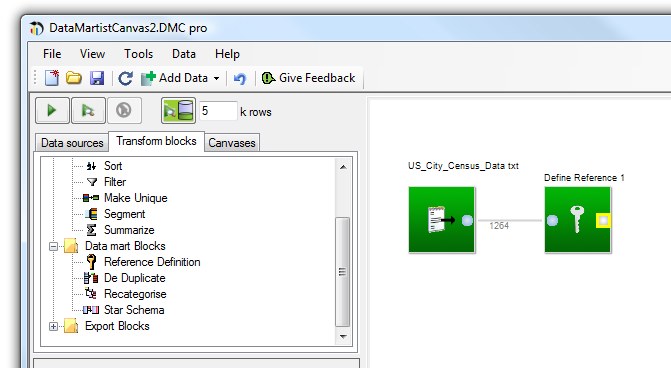
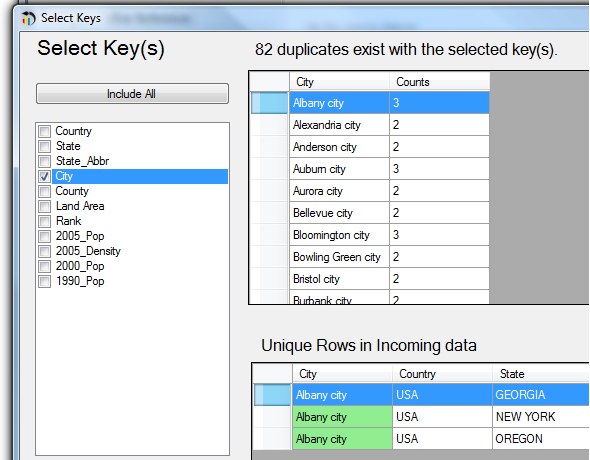
When we edit the reference block, we can select which column we want to use as a key, and the result of this selection is immediately shown. In this case, if we select only the city column as a key, we will find that that there are a number of duplicates (since cities of the same name exist in different states.) These duplicates are shown to use in the preview pane.
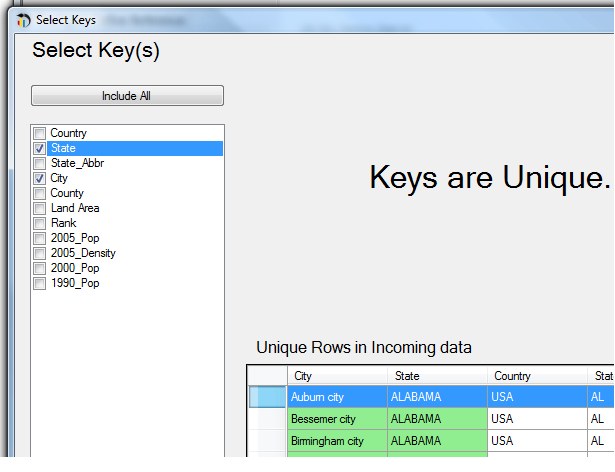
If we then add the STATE column to the key selection, we see that the selected key is now unique.
Mapping away duplicate reference
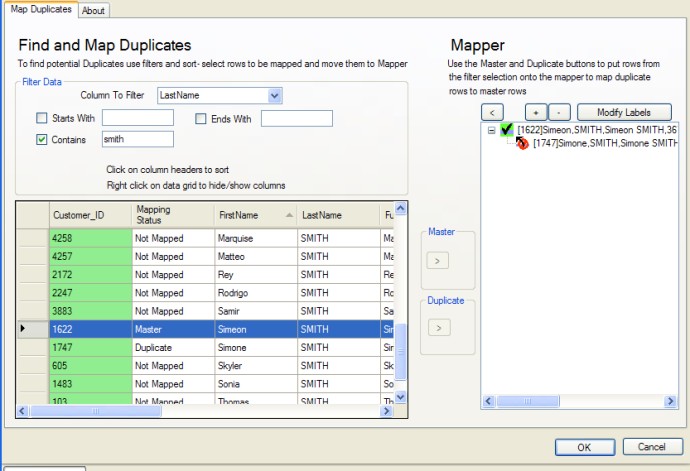
Once we have established a reference using a reference block, it is possible to use a deduplication block to map away duplicate references. If we look at an example of a customer list where we have multiple records for the same customer- we can map away these duplicates by first connecting the customer list to a reference block, and establishing the key- In this case simply the CUSTOMER_ID field.
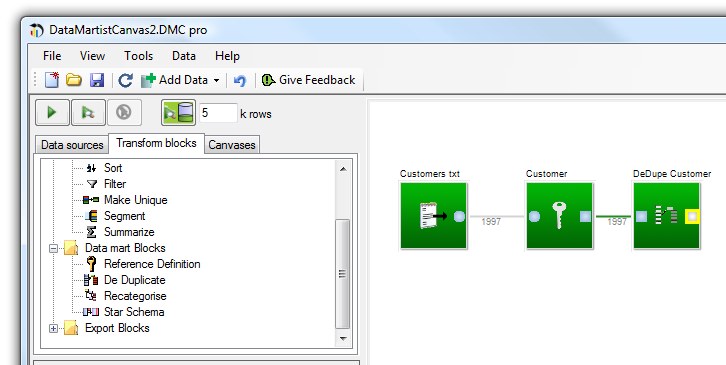
Then by editing the deduplication block configuration, we find that we can filter, and sort the records to find duplicates. We first establish which of the duplicate records we want to declare is the "master" record, and then we map all the other duplicates to this record. Now, when the result of this deduplication block is fed into a star schema block, the resulting join will be between the fact table and the master record whenever one of the duplicate keys is found in the fact table.