Help and Support > Table of Contents > Using the data profiler
Using the data profiler
The data profiler allows you to quickly access the data quality and contents of a data set anywhere on the datamartist canvas. To use the data profiler:
- Select a stub by clicking on either the stub circle on the block or on a connector line between blocks.
- Select the data profiler tab at the lower left of the screen, directly underneith the data viewer tab,
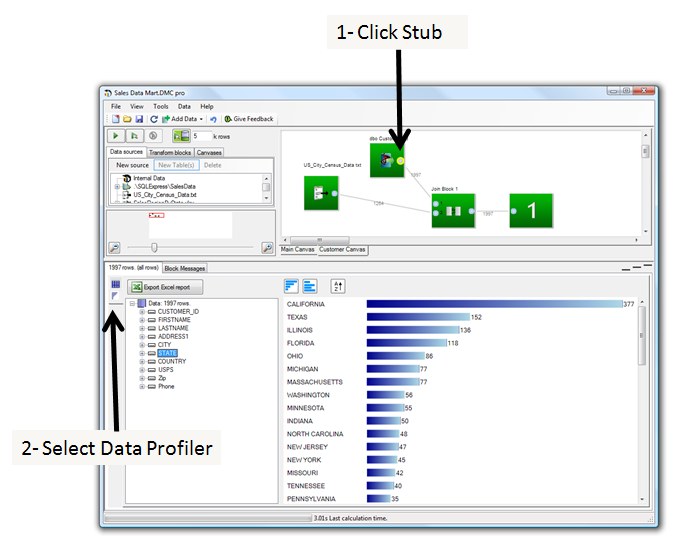
When the data profiler tab is selected, Datamartist runs an analysis on the selected data set- and then displays an overview of each column within the data set defining the following:
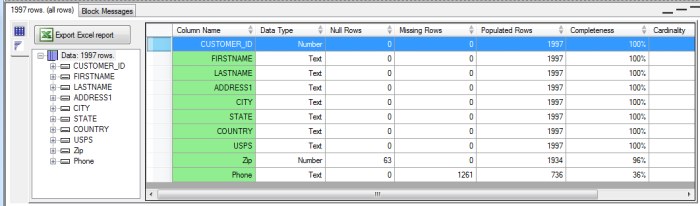
- Column Name- the name of the column being profiled.
- Data Type - the declared data type for the column
- Null rows- the count of rows that contain the null value.
- Missing rows- for string types the count of rows containing the empty string.
- Populated rows- the count of rows that are not Null or missing.
- Completeness- the percentage of rows that are Populated (Populated/Total Rows).
- Cardinality- the number of unique values contained in the row.
- Uniqueness- the cardinality divided by the number of populated rows.
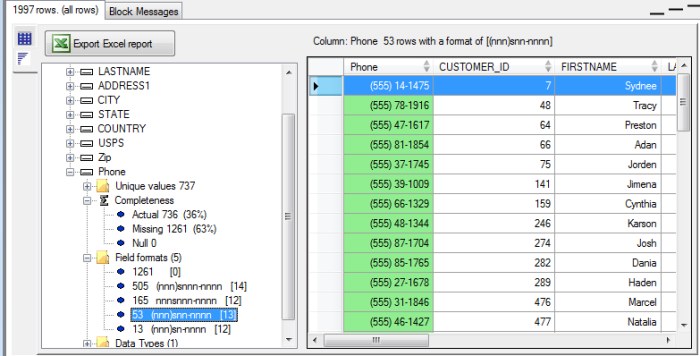
In the example below, we can see that while most columns are complete, and the Customer_ID column is both complete and 100% unique (which is a good thing for the ID) the zip gode is only 96% complete, and the phone number only 36%.
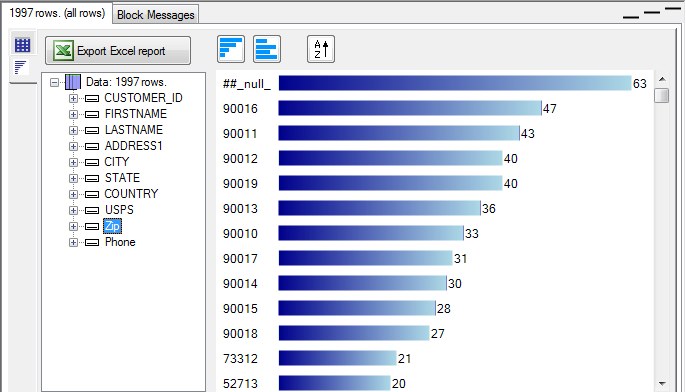
By selecting the Zip column icon in the tree view on the left, and selecting the unique values metric we can see the distribution of row counts by value for this column
Field Formats
The data profiler also parses the values in each column using a format code as follows- this allows you to at a glance understand issues with poorly formed strings (such as Zip codes or Phone numbers)- a- Denotes a letter of the alphabet
- n- Denotes a digit (0 to 9)
- s- Denotes white space (such as spaces)
- Punctuation is passed through to the format string so that you can see locations of brackets and dashes etc.
So if we drill down into the field format metric, we'll find row counts for each unique field format based on the above codes. A three digit number will appear as "nnn" for example, and a standard North American phone number with spaces would appear as (nnn) nnn-nnnn. We can see from this example, that we have some invalid phone numbers in our data: