Help and Support > Table of Contents > How data is transformed
How data is transformed on the canvas
Data that is on the inputs of a block is transformed within the block on the Datamartist canvas, and a new data set is made available on the outputs of that block for other blocks to use for their transformations.
If we look at a very simple example, lets suppose that we use a calculation block to calculate ages from birthdates:
Age in Years = TRUNC( ( [Birth Date] - NOW() )/365)
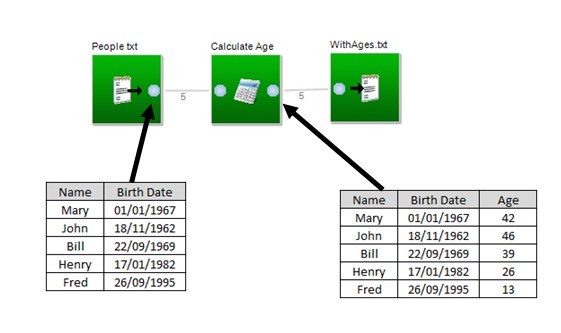
The numbers beside the connectors tell us the number of rows in the data set being passed by the connector. If we consider the blocks from left to right:
- Text Import block - it does not have any input stubs (no stubs on the left or top) because it gets its data from the text file that has been specified.
- Calculation block, its input is connected to the text import block so it uses the contents of the text file to generate its output data set. The calculation block does not modify the input file, it generates a new data set, which in this case has an additional column Age.
- Text Export Block has one input, and no outputs, since it generates a new text file containing the data on its input (which is the result of the Calculation block).
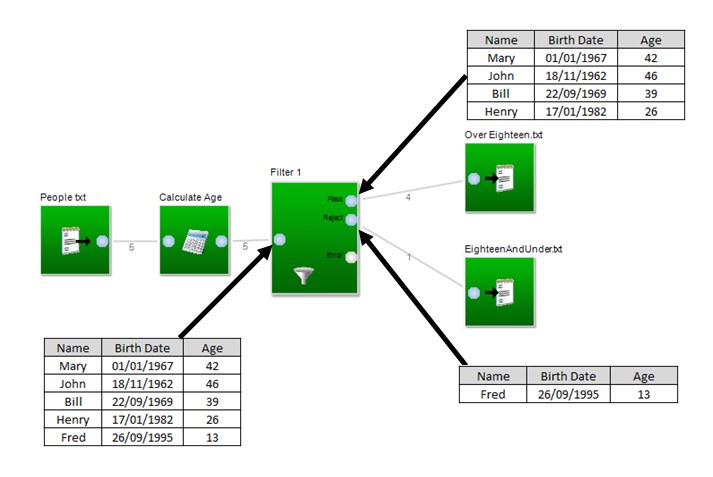
In this first example, the number of rows before and after the Calculation block remains the same. This will always be the case for a calculation block since the calculation block performs the calculation on every row. Depending on the block, however, there maybe be fewer rows, or the rows may be divided accross multiple output stubs. We can see this if we add a filter block to this example:
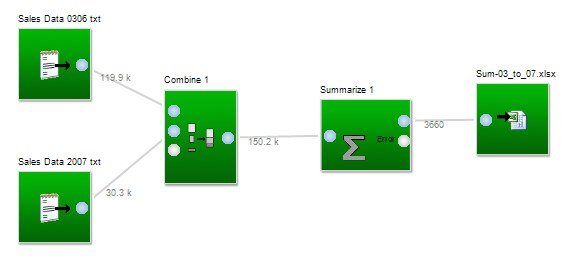
In another example below, sales data from multiple years are combined together, then this data set is summarized, ignoring the customer field, and summing quantity and averaging price by product and month to reduce the data volume from 150 000 rows to approximately 3000. This type of operation is particularly useful when dealing with data files containing millions of rows.